Context:
Surpassing Frontier Performance with Fusion
https://news.ycombinator.com/item?id=48525392
And a slightly better UI here: https://openrouter.ai/fusion
On OpenRouter's fusion API your request is routed to several models simultaneously and a judge model combines their answers into a final response. This significantly boosts performance, at the cost of time (at least on the one benchmark they tested, a deep research benchmark).
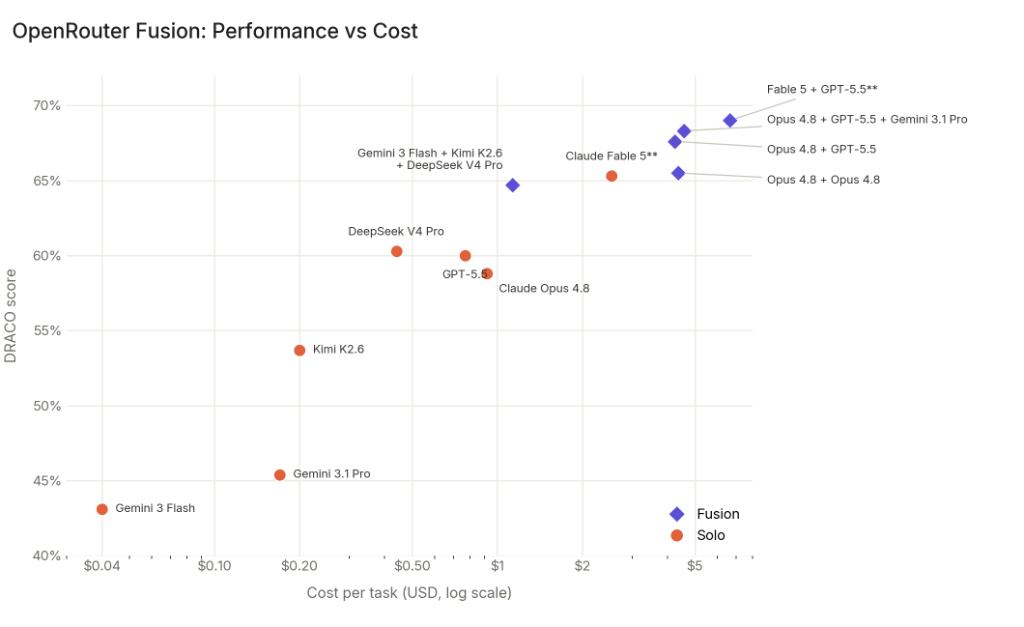
They have a Budget preset consisting of 3 cheaper models (which roughly matches Fable on that benchmark, costing half as much), and a Quality preset of 3 expensive ones (which beats Fable, but costs twice as much as Fable).
Pareto graph: https://openrouter.ai/blog/images/blog/fusion-benchmark-cost...
{kind=link}
Curiously, fusing a model with itself also boosted performance (2xOpus4.8 roughly matching Fable on the benchmark, but costing twice as much as Fable). There's a further, smaller gain from mixing different models. The main gain seems to be from additional test time compute.
Would love to see more research on this, especially focusing on the cheap models that came out recently (e.g. Fusing DSV4 with itself, or with Mimo), and to see what the tradeoffs look like between running a fusion (parallel test time compute) vs increased reasoning or turns.
> Curiously, fusing a model with itself also boosted performance
Back in the GPT2 to GPT3 era this was a pretty common thing to do. You are effectively taking more samples from the space of likely outputs. If your model can do the task 60% of the time just take 5-10 samples and implement some kind of majority voting
It became less common to use as models got high accuracy on problems where combining results is trivial. But with a more complex judge (a competent LLM) you can still get better results by just sampling more of the output space and picking out the best aspects
Interesting how well a panel of Fable 5 + GPT 5.5 beats the frontier of either one, but if you add Gemini into the mix the panel of three performs worse, not better. To me that sounds like Gemini is worse at the given tasks but better at convincing judges of its solutions. Oh and a Panel of 2 Opus 4.8 models is almost exactly as good as one Fable 5. That smells suspicious. Do we know if that might simply be what Anthropic is doing behind the curtain?
Yeah, GPT 5.5 + Fable beating either individually is belivable, but 2x Opus > Fable is what makes me a bit dubious about the whole thing. They might be measuring skills that are too specific or benefit a lot from more tokens being thrown at them. Also Claude Code (the harness) is not the best at the moment, that might be part of it as well?
What throws me off is DeepSeek beating both Opus 4.8 and GPT 5.5.
That definitely doesn't sound right.
> Interesting how well a panel of Fable 5 + GPT 5.5 beats the frontier of either one, but if you add Gemini into the mix the panel of three performs worse
I'm not seeing that? Did you maybe misread the #2 ranked one as Fable + GPT + Gemini? It's actually Opus + GPT + Gemini.
> Oh and a Panel of 2 Opus 4.8 models is almost exactly as good as one Fable 5. That smells suspicious. Do we know if that might simply be what Anthropic is doing behind the curtain?
I wouldn't be surprised if Fable/Mythos is a model distilled from a Panel/Council of Claude instances. Recursive self improvement is something all AI labs must be working on in some way or another.
I don't know if it is still the case with current models, but a few generations back Microsoft had some research results where asking a model to iterate N times would significantly improve performance, with the optimal point being 4 iterations.
I think there's a sweet spot for it. If a model can't do a task, iterating won't help. If a model can do it reliably, there's no need to iterate.
If it can do it, but unreliably, that's where you would get major gains from iterating. I think the Chinese models are in that sweet spot, for many tasks. I would love to test that.
I started working on my own fusion system yesterday. I'm not sure how to benchmark it though.
The thing I'm most interested in is reliability. Going from 90% to 95% on a benchmark doesn't seem like much but you've cut the error rate in half.
> but a few generations back
Out of interest: Was this still before CoT/thinking-mode became the norm?