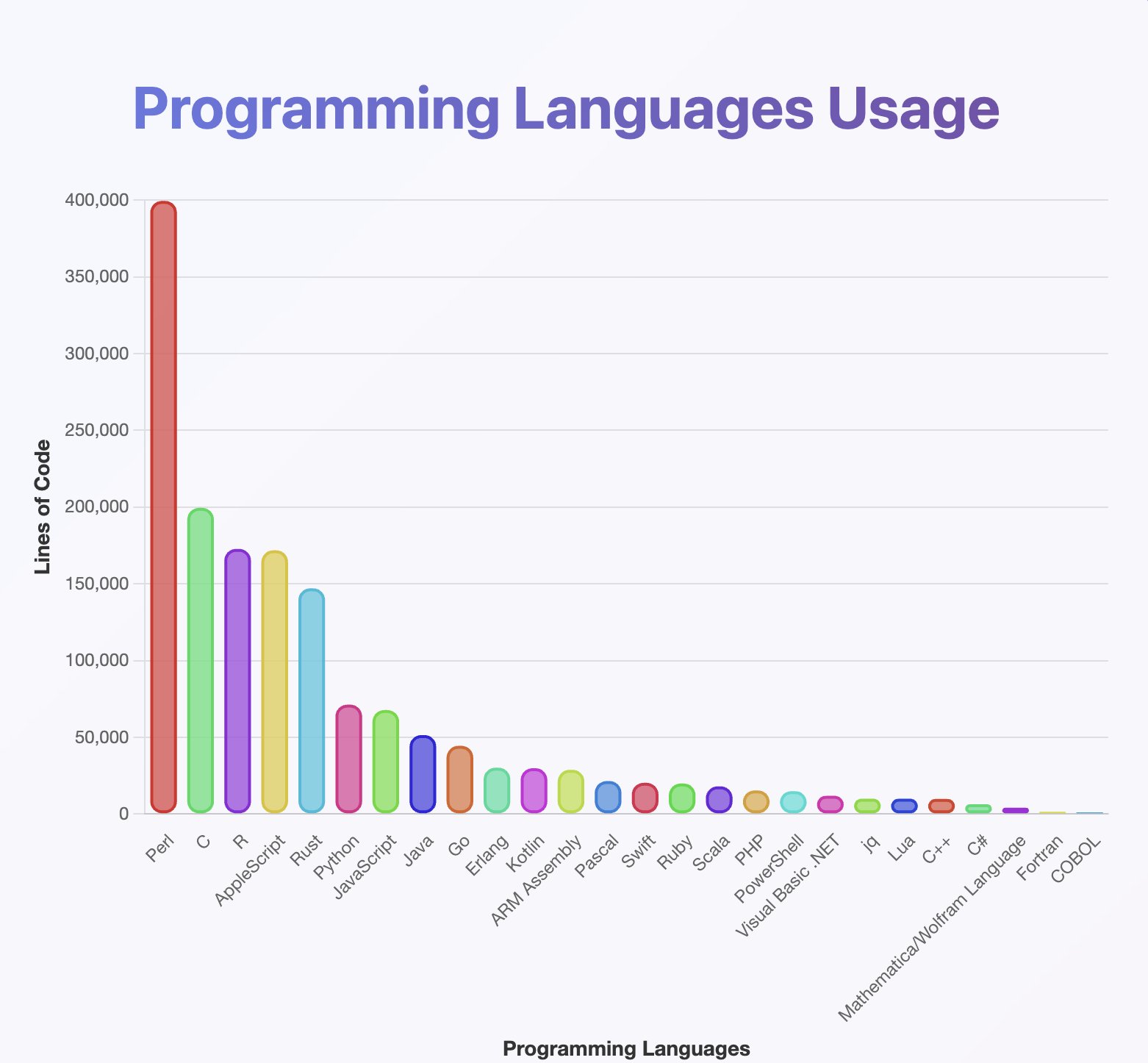
OP seems to have run a programming language detector on the generated texts, and made a graph of programming language frecuencies: https://pbs.twimg.com/media/Gx2kvNxXEAAkBO0.jpg?name=orig
{kind=link}
As a result, OP seems to think the model was trained on a lot of Perl: https://xcancel.com/jxmnop/status/1953899440315527273#m
LOL! I think these results speak more to the flexibility of Perl than any actual insight on the training data! After all, 93% of inkblots are valid Perl scripts: https://www.mcmillen.dev/sigbovik/
I don't understand why Perl, R, and AppleScript rank so much higher than their observed use.
Perl and Applescript are close to natural language. R is close to plain maths
https://en.wikipedia.org/wiki/Black_Perl
The prominence of AppleScript ought to have been a pretty big red flag: the author seems to be claiming the model was trained on more AppleScript than Python, which simply can’t be true.
Ironically LLMs seem pretty bad at writing AppleScript, I think because (i) the syntax is English-like but very brittle, (ii) the application dictionaries are essential but generally not on the web, and (iii) most of the AppleScript that is on the web has been written by end users, often badly.
It seems to be an error with the classifier. Sorry everyone. I probably shouldn't have posted that graph; I knew it was buggy, I just thought that the Perl part might be interesting to people.
Here's a link to the model if you want to dive deeper: https://huggingface.co/philomath-1209/programming-language-i...
R being so high makes no sense to me either.
I think as of the last Stack Overflow developer survey, it only had ~4% market share…
I say this as an R user who spams LLMs with R on a daily basis.
That inkblot thing can be created for any language.
How? E.g. I doubt an inkblot can produce a valid C# program.
They are not full programs, just code translating to numbers and strings.
I used an LLM to generate an inkblot that translates to a Python string and number along with verification of it, which just proves that it is possible.
what are you talking about?
the way that the quoted article creates Perl programs is through OCRing the inkblots (i.e. creating almost random text) and then checking that result to see if said text is valid Perl
it's not generating a program that means anything
Okay, and I created inkblots that mean "numbers"[1] and "strings" in Python.
> it's not generating a program that means anything
Glad we agree.
[1] Could OCR those inkblots (i.e. they are almost random text)
No, asking an LLM to generate the inkblot is the same as asking the LLM to write a string and then obfuscating it in an inkblot.
OCRing literal random inkblots will not produce valid C (or C# or python) code, but it will prodce valid Perl most of the time, because Perl is weird, and that is funny.
It's not about obfuscating text in inkblot, it's about almost any string being a valid Perl program, which is not the case for most languages
Edit0: here: https://www.mcmillen.dev/sigbovik/
Okay, my bad.
> it's about almost any string being a valid Perl program
Is this true? I think most random unquoted strings aren't valid Perl programs either, am I wrong?
Yes. That was the whole point of the original comment you were misunderstanding.
Because of the flexibility of Perl and heavy amount of symbol usage, you can in fact run most random combinations of strings and they’ll be valid Perl.
Copying from the original comment: https://www.mcmillen.dev/sigbovik/
Most random unquoted strings are certainly not valid Python programs. I don't know Perl well enough to say anything about that but I know what you're saying certainly isn't true with Python.
Of the powerset of all operators and inputs, how many can be represented in any programming language?
What percent of all e.g. ASCII or Unicode strings are valid expressions given a formal grammar?
Honestly these results may say as much about the classifier as they do about the data they’re classifying.
Jack has a lot of really bad takes and frequently makes lots of mistakes. Honestly, I don't know why people take him seriously.
I mean you can go read his blog post that's pinned where he argues that there's no new ideas and it is all data. He makes the argument that architecture doesn't matter, which is just so demonstrably false that it is laughable. He's a scale maximalist.
I also expect an AI researcher from a top university to not make such wild mistakes
I mean if you go read the instruct paper on page 2 you'll see Where in Christiano you'll find I mean this is just obviously wrong. It is so obviously wrong it should make the person saying it second guess themselves (which is categorically the same error you're pointing out).I'm sure we can trace the idea back to the 80's if not earlier. This is the kind of take I'd expect a non-researcher to have, but not someone with two dozen NLP papers. The Instruct-GPT paper was just the first time someone integrated RLHF into a LLM (but not a LM).
Maybe a better article is the one he wrote on Super Intelligence From First Principles. As usual, when someone says "First Principles" you bet they're not gonna start from First Principles... I guess this makes sense in CS since we index from 0
[0] https://arxiv.org/abs/2203.02155
[Christiano et al] https://arxiv.org/abs/1706.03741
[Stiennon eta al] https://arxiv.org/abs/2009.01325
[Akrour et al (2012)] https://arxiv.org/abs/1208.0984
Hi again. I had already written about this later in my blog post (which is unrelated to this thread), but the point was that RLHF hadn't been applied to language models at scale until InstructGPT. I edited the post just now to clarify this. Thanks for the feedback!